O futuro da inteligência artificial chegou: GPT 5.5 já disponível na Neuriz.com

Capacidades do modelo
A OpenAI está construindo a infraestrutura global para IA agente, possibilitando que pessoas e empresas em todo o mundo realizem trabalhos com IA. No último ano, vimos a IA acelerar drasticamente a engenharia de software. Com o GPT-5.5 no Codex e o ChatGPT, essa mesma transformação está começando a se estender à pesquisa científica e ao trabalho mais amplo que as pessoas realizam em computadores.
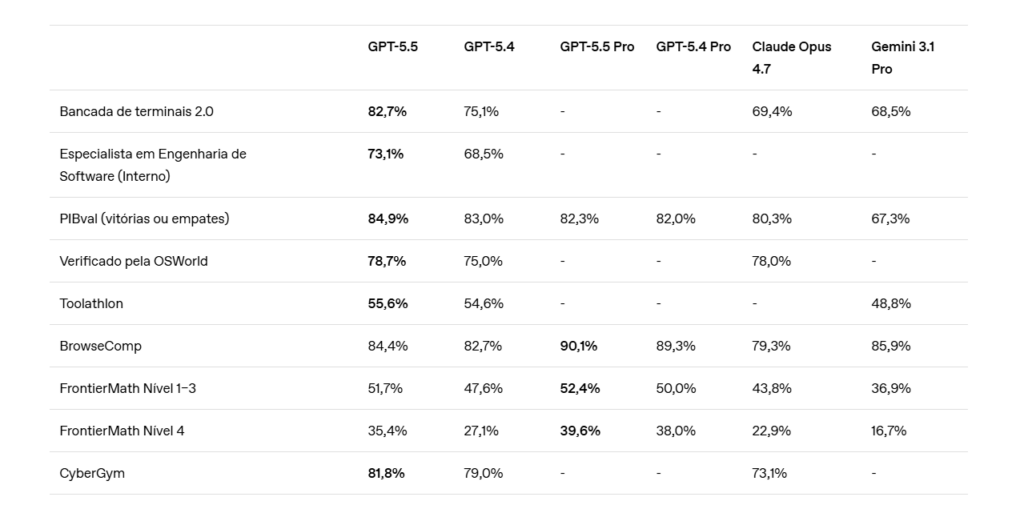
Nessas áreas, o GPT-5.5 não é apenas mais inteligente; ele é mais eficiente na resolução de problemas, frequentemente alcançando resultados de maior qualidade com menos tokens e menos tentativas. No Índice de Codificação da Artificial Analysis, o GPT-5.5 oferece inteligência de ponta pela metade do custo de modelos de codificação de vanguarda concorrentes.
Codificação agêntica
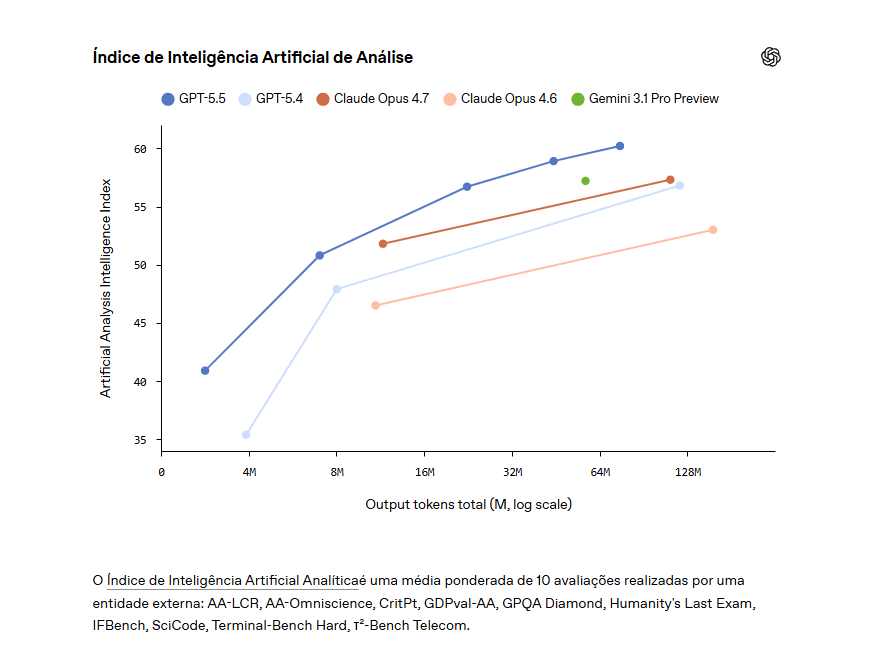
O GPT-5.5 é o nosso modelo de codificação agentiva mais robusto até o momento. No Terminal-Bench 2.0, que testa fluxos de trabalho complexos em linha de comando que exigem planejamento, iteração e coordenação de ferramentas, ele alcança uma precisão de última geração de 82,7%. No SWE-Bench Pro , que avalia a resolução de problemas reais do GitHub, ele atinge 58,6%, resolvendo mais tarefas de ponta a ponta em uma única passagem do que os modelos anteriores. No Expert-SWE , nossa avaliação interna de fronteira para tarefas de codificação de longo prazo com um tempo médio estimado de conclusão humana de 20 horas, o GPT-5.5 também supera o GPT-5.4.
Em todas as três avaliações, o GPT-5.5 supera as pontuações do GPT-5.4 usando menos tokens.
Pesquisa científica
O GPT-5.5 também demonstra ganhos em fluxos de trabalho de pesquisa científica e técnica, que exigem mais do que simplesmente responder a uma pergunta complexa. Os pesquisadores precisam explorar uma ideia, coletar evidências, testar hipóteses, interpretar resultados e decidir o que tentar em seguida. O GPT-5.5 é mais eficiente em persistir ao longo desse ciclo do que outros modelos.
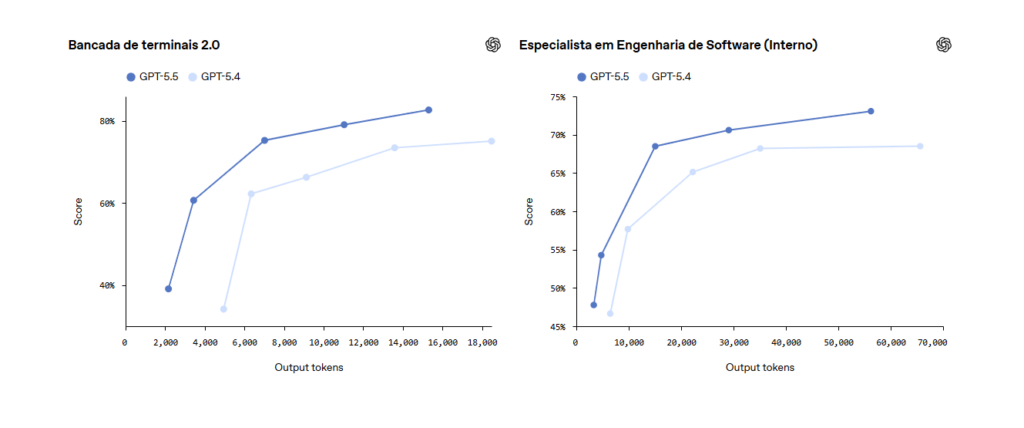
Notavelmente, o GPT-5.5 demonstra uma clara melhoria em relação ao GPT-5.4 no GeneBench .(abre em uma nova janela), uma nova avaliação focada na análise de dados científicos em múltiplas etapas nas áreas de genética e biologia quantitativa. Esses problemas exigem que os modelos raciocinem sobre dados potencialmente ambíguos ou errôneos com mínima supervisão, lidem com obstáculos realistas como fatores de confusão ocultos ou falhas no controle de qualidade e implementem e interpretem corretamente métodos estatísticos modernos. O desempenho do modelo é impressionante, considerando que as tarefas aqui frequentemente correspondem a projetos de vários dias para especialistas científicos.
Eficiência de inferência de próxima geração
Para que o GPT-5.5 tivesse a mesma latência do GPT-5.4, foi necessário repensar a inferência como um sistema integrado, e não como um conjunto de otimizações isoladas. O GPT-5.5 foi projetado, treinado e implementado em sistemas NVIDIA GB200 e GB300 NVL72. O Codex e o GPT-5.5 foram fundamentais para alcançarmos nossas metas de desempenho. O Codex ajudou a equipe a avançar mais rapidamente da ideia à implementação com benchmarks, esboçando abordagens, conectando experimentos e ajudando a identificar quais otimizações mereciam um investimento maior. O GPT-5.5 ajudou a encontrar e implementar melhorias importantes na própria infraestrutura. Em resumo, o modelo ajudou a aprimorar a infraestrutura que o suporta.
Uma dessas melhorias foi o balanceamento de carga e as heurísticas de particionamento. Antes do GPT-5.5, dividíamos as requisições em um acelerador em um número fixo de partes para distribuir o trabalho entre os núcleos de computação, garantindo que requisições grandes e pequenas pudessem ser executadas na mesma GPU. No entanto, um número predeterminado de partes estáticas não é o ideal para todos os padrões de tráfego. Para melhor utilizar as GPUs, a Codex analisou semanas de padrões de tráfego de produção e desenvolveu algoritmos heurísticos personalizados para particionar e balancear o trabalho de forma otimizada. O esforço teve um impacto significativo, aumentando a velocidade de geração de tokens em mais de 20%.
Promovendo a cibersegurança para a segurança de todos.
Preparar o mundo para modelos que sejam muito bons em encontrar e corrigir vulnerabilidades de segurança é um trabalho de equipe e exigirá que todo o ecossistema trabalhe arduamente para construir resiliência, com acesso democratizado aos modelos e implantação iterativa para a próxima era da defesa cibernética .
Os modelos de vanguarda estão se tornando cada vez mais capazes em cibersegurança. Essas capacidades serão amplamente distribuídas e acreditamos que o melhor caminho a seguir é garantir que possam ser utilizadas para acelerar a defesa cibernética e fortalecer o ecossistema.
O GPT-5.5 é um passo incremental, porém importante, em direção à IA, capaz de solucionar alguns dos desafios mais complexos do mundo, como a segurança cibernética. Com o GPT-5.2, lançado em dezembro, implementamos proativamente as salvaguardas cibernéticas necessárias para limitar o potencial abuso cibernético de nossos modelos; agora, com o GPT-5.5, estamos implementando classificadores mais rigorosos para potenciais riscos cibernéticos, o que alguns usuários podem considerar inicialmente incômodo, enquanto os ajustamos ao longo do tempo.
Identificamos a cibersegurança como uma categoria em nossa Estrutura de Preparação .(abre em uma nova janela)Ao longo dos anos, nossos modelos foram sendo aprimorados gradualmente, enquanto desenvolvíamos e calibramos medidas de mitigação de forma iterativa, para sermos capazes de lançar, de forma responsável, modelos com recursos significativos de segurança cibernética.
- Estamos implementando medidas de segurança líderes do setor para esse nível de capacidade cibernética. Introduzimos medidas de segurança específicas para cibersegurança pela primeira vez com o GPT-5.2 .(abre em uma nova janela)No ano passado, implementamos o GPT-5.5, que continuamos a testar, aprimorar e desenvolver em implantações subsequentes. Para o GPT-5.5, projetamos controles mais rigorosos em torno de atividades de alto risco, solicitações cibernéticas sensíveis e adicionamos proteções contra uso indevido repetido. O amplo acesso é possível graças aos nossos investimentos em segurança do modelo, uso autenticado e monitoramento de uso não permitido. Trabalhamos com especialistas externos durante meses para desenvolver, testar e aprimorar a robustez dessas salvaguardas. Com o GPT-5.5, garantimos que os desenvolvedores possam proteger seu código com facilidade, ao mesmo tempo em que implementamos controles mais fortes em torno dos fluxos de trabalho cibernéticos com maior probabilidade de causar danos por agentes maliciosos.
- Estamos ampliando o acesso para acelerar a defesa cibernética em todos os níveis. Estamos disponibilizando nossos modelos de cibersegurança permissiva por meio do Acesso Confiável para Cibersegurança , começando com o Codex, que inclui acesso expandido aos recursos avançados de cibersegurança do GPT-5.5 com menos restrições para usuários verificados que atendam a determinados sinais de confiança .(abre em uma nova janela)No lançamento, organizações responsáveis pela defesa de infraestruturas críticas podem solicitar acesso a modelos cibernéticos permissivos como o GPT-5.4-Cyber, atendendo a rigorosos requisitos de segurança para usar esses modelos na proteção de seus sistemas internos. Isso proporciona a uma ampla gama de defensores verificados ferramentas mais poderosas para o trabalho legítimo de segurança, com menos atrito desnecessário, garantindo a democratização do acesso a importantes recursos de defesa. Os usuários podem solicitar acesso confiável em chatgpt.com/cyber .(abre em uma nova janela)Reduzir recusas desnecessárias ao usar o GPT-5.5 para tarefas defensivas verificadas.
- Estamos trabalhando com parceiros governamentais para ajudar a proteger infraestruturas críticas para o público. Juntos, estamos explorando como a IA avançada pode apoiar o trabalho de defesa de autoridades confiáveis responsáveis por sistemas essenciais para a população, desde os sistemas digitais que protegem dados importantes dos contribuintes até a rede elétrica e o abastecimento de água em comunidades locais.
Consideramos as capacidades biológicas/químicas e de cibersegurança do GPT-5.5 como de alto nível em nossa Estrutura de Preparação .(abre em uma nova janela)Embora o GPT-5.5 não tenha atingido o nível de capacidade crítica de cibersegurança, nossas avaliações e testes mostraram que suas capacidades de cibersegurança representam um avanço em comparação com o GPT-5.4.
Além disso, o GPT-5.5 passou por todo o nosso processo de segurança e governança antes do lançamento, incluindo avaliações de preparação, testes específicos de domínio, novas avaliações direcionadas para recursos avançados de biologia e cibersegurança, e testes robustos com especialistas externos. Compartilhamos mais detalhes no cartão do sistema GPT-5.5 .(abre em uma nova janela).
Este trabalho reflete nossa abordagem mais ampla de resiliência da IA, que acreditamos ser necessária à medida que as capacidades dos modelos avançam. Queremos que a IA poderosa esteja disponível para as pessoas que a utilizam para defender sistemas, instituições e o público. O caminho viável é o acesso confiável, salvaguardas robustas que se adaptem à capacidade e a capacidade operacional para detectar e responder a usos indevidos graves.
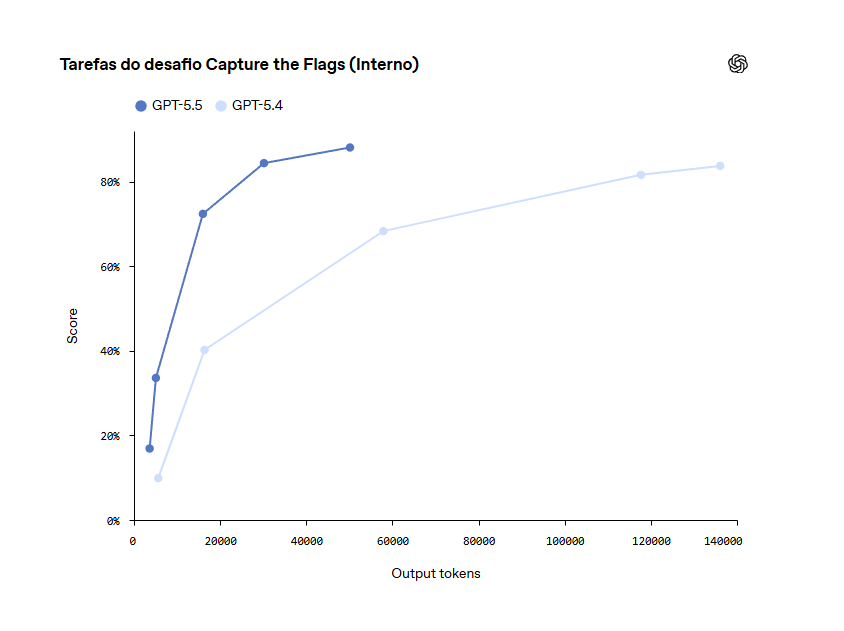
Avaliações
Codificação
| Avaliação | GPT-5.5 | GPT‑5.4 | GPT-5.5 Pro | GPT‑5.4 Pro | Claude Opus 4.7 | Gemini 3.1 Pro |
| SWE-Bench Pro (Público) * | 58,6% | 57,7% | – | – | 64,3% | 54,2% |
| Bancada de terminais 2.0 | 82,7% | 75,1% | – | – | 69,4% | 68,5% |
| Especialista em Engenharia de Software (Interno) | 73,1% | 68,5% | – | – | – | – |
* Os laboratórios observaram evidências de memorização .(abre em uma nova janela)nesta avaliação
Profissional
| Avaliação | GPT-5.5 | GPT‑5.4 | GPT-5.5 Pro | GPT‑5.4 Pro | Claude Opus 4.7 | Gemini 3.1 Pro |
| PIBval (vitórias ou empates) | 84,9% | 83,0% | 82,3% | 82,0% | 80,3% | 67,3% |
| Agente Financeiro v1.1 | 60,0% | 56,0% | – | 61,5% | 64,4% | 59,7% |
| Tarefas de Modelagem de Banco de Investimento (Internas) | 88,5% | 87,3% | 88,6% | 83,6% | – | – |
| OfficeQA Pro | 54,1% | 53,2% | – | – | 43,6% | 18,1% |
Uso do computador e visão
| Avaliação | GPT-5.5 | GPT‑5.4 | GPT-5.5 Pro | GPT‑5.4 Pro | Claude Opus 4.7 | Gemini 3.1 Pro |
| Verificado pela OSWorld | 78,7% | 75,0% | – | – | 78,0% | – |
| MMMU Pro (sem ferramentas) | 81,2% | 81,2% | – | – | – | 80,5% |
| MMMU Pro (com ferramentas) | 83,2% | 82,1% | – | – | – | – |
Uso da ferramenta
| Avaliação | GPT-5.5 | GPT‑5.4 | GPT-5.5 Pro | GPT‑5.4 Pro | Claude Opus 4.7 | Gemini 3.1 Pro |
| BrowseComp | 84,4% | 82,7% | 90,1% | 89,3% | 79,3% | 85,9% |
| Atlas MCP** | 75,3% | 70,6% | – | – | 79,1% | 78,2% |
| Toolathlon | 55,6% | 54,6% | – | – | – | 48,8% |
| Bancada Tau2 Telecom*** (instruções originais) | 98,0% | 92,8% | – | – | – | – |
** MCP Atlas: resultados da Scale AI após a última atualização de abril de 2026.
*** Tau2-bench telecom: resultados para 5.5 e 5.4 com os prompts originais, ou seja, sem ajuste de prompt. Isso omite resultados de outros laboratórios que foram avaliados com ajustes de prompt.
Acadêmico
| Avaliação | GPT-5.5 | GPT‑5.4 | GPT-5.5 Pro | GPT‑5.4 Pro | Claude Opus 4.7 | Gemini 3.1 Pro |
| Banco de genes | 25,0% | 19,0% | 33,2% | 25,6% | – | – |
| FrontierMath Nível 1–3 | 51,7% | 47,6% | 52,4% | 50,0% | 43,8% | 36,9% |
| FrontierMath Nível 4 | 35,4% | 27,1% | 39,6% | 38,0% | 22,9% | 16,7% |
| BixBench | 80,5% | 74,0% | – | – | – | – |
| Diamante GPQA | 93,6% | 92,8% | – | 94,4% | 94,2% | 94,3% |
| O Último Exame da Humanidade (sem ferramentas) | 41,4% | 39,8% | 43,1% | 42,7% | 46,9% | 44,4% |
| O Último Exame da Humanidade (com ferramentas) | 52,2% | 52,1% | 57,2% | 58,7% | 54,7% | 51,4% |
Segurança cibernética
| Avaliação | GPT-5.5 | GPT‑5.4 | GPT-5.5 Pro | GPT‑5.4 Pro | Claude Opus 4.7 | Gemini 3.1 Pro |
| Tarefas do desafio Capture the Flags (Interno)**** | 88,1% | 83,7% | – | – | – | – |
| CyberGym | 81,8% | 79,0% | – | – | 73,1% | – |
**** Uma expansão dos CTFs mais difíceis usados em placas de sistema com desafios adicionais de alta dificuldade.
Contexto longo
| Avaliação | GPT-5.5 | GPT‑5.4 | GPT-5.5 Pro | GPT‑5.4 Pro | Claude Opus 4.7 | Gemini 3.1 Pro |
| Graphwalks BFS 256k f1 | 73,7% | 62,5% | – | – | 76,9% | – |
| Graphwalks BFS 1mil f1 | 45,4% | 9,4% | – | – | 41,2% (Opus 4.6) | – |
| Pais do Graphwalk 256k f1 | 90,1% | 82,8% | – | – | 93,6% | – |
| Pais do Graphwalks 1 milhão f1 | 58,5% | 44,4% | – | – | 72,0% (Opus 4.6) | – |
| OpenAI MRCR v2 8 agulhas 4K-8K | 98,1% | 97,3% | – | – | – | – |
| OpenAI MRCR v2 8 agulhas 8K-16K | 93,0% | 91,4% | – | – | – | – |
| OpenAI MRCR v2 8 agulhas 16K-32K | 96,5% | 97,2% | – | – | – | – |
| OpenAI MRCR v2 8 agulhas 32K-64K | 90,0% | 90,5% | – | – | – | – |
| OpenAI MRCR v2 8 agulhas 64K-128K | 83,1% | 86,0% | – | – | – | – |
| OpenAI MRCR v2 8 agulhas 128K-256K | 87,5% | 79,3% | – | – | 59,2% | – |
| OpenAI MRCR v2 8 agulhas 256K-512K | 81,5% | 57,5% | – | – | – | – |
| OpenAI MRCR v2 8 agulhas 512K-1M | 74,0% | 36,6% | – | – | 32,2% | – |
Raciocínio abstrato
| Avaliação | GPT-5.5 | GPT‑5.4 | GPT-5.5 Pro | GPT‑5.4 Pro | Claude Opus 4.7 | Gemini 3.1 Pro |
| ARC-AGI-1 (Verificado) | 95,0% | 93,7% | – | 94,5% | 93,5% | 98,0% |
| ARC-AGI-2 (Verificado) | 85,0% | 73,3% | – | 83,3% | 75,8% | 77,1% |









Publicar comentário